
Современные языковые модели, такие как DeepSeek, GPT-4 или Llama 3, могут значительно улучшить бизнес-процессы: автоматизировать поддержку клиентов, анализировать документы и даже генерировать код. Но как развернуть такую модель на своих серверах, чтобы сохранить контроль над данными и обеспечить безопасность?
В этой статье разберем пошаговый процесс внедрения LLM (Large Language Model) в корпоративную инфраструктуру.
1. Зачем развертывать ИИ на своих серверах?
🔹 Преимущества локального развертывания:
✅ Конфиденциальность – данные не уходят к сторонним API (как у OpenAI).
✅ Кастомизация – можно дообучить модель под свои задачи.
✅ Стабильность – не зависит от внешних сервисов и лимитов.
✅ Экономия – долгосрочно дешевле, чем платные подписки.
🔹 Где применять?
- Чат-боты для внутренней поддержки.
- Анализ документов (договоры, отчеты).
- Генерация кода (Copilot-аналоги).
- Голосовые ассистенты для call-центров.
2. Выбор модели: DeepSeek, Llama 3, Mistral или GPT-4?
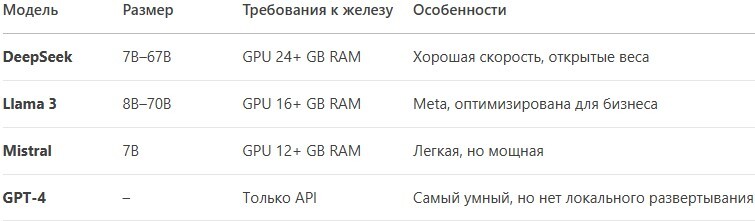
👉 DeepSeek – хороший баланс между производительностью и требованиями.
3. Какое оборудование нужно?
🔹 Минимальные требования:
- Сервер с GPU (NVIDIA A100 / RTX 4090 / H100).
- Оперативная память: 32+ GB (для 7B-моделей).
- Диск: SSD 100+ GB (модели весят 20–140 GB).
🔹 Облако vs. Локальный сервер
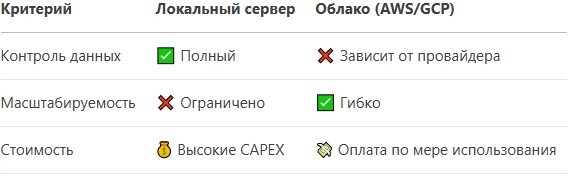
Вывод: Если критична конфиденциальность – свой сервер. Если нужна гибкость – облако.
4. Пошаговое развертывание DeepSeek на сервере
🔹 Шаг 1: Установка Python и CUDA
sudo apt update && sudo apt install python3 python3-pippip install torch transformers accelerate
(Для NVIDIA GPU нужен CUDA Toolkit).
🔹 Шаг 2: Загрузка модели
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/deepseek-llm-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
🔹 Шаг 3: Запуск инференса
input_text = "Как автоматизировать отчётность в компании?"inputs = tokenizer(input_text, return_tensors="pt").to("cuda")outputs = model.generate(**inputs, max_length=200)print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🔹 Шаг 4: Интеграция с бизнес-системами
- REST API (FastAPI / Flask).
- Подключение к корпоративному чату (Slack / Teams).
- Автоматизация обработки документов.
5. Оптимизация производительности
- Квантование (уменьшение модели в 2–4 раза без потери качества).
- Использование vLLM – ускорение генерации текста.
- Кеширование запросов – если вопросы повторяются.
6. Безопасность и контроль
🔐 Как защитить корпоративные данные?
- Запуск модели в изолированном контуре.
- Шифрование запросов (TLS).
- Логирование всех обращений к модели.
7. Альтернативы: готовые корпоративные решения
Если нет ресурсов на развертывание своей модели:
- DeepSeek API (если можно отправлять данные).
- Azure OpenAI (частные облачные развертывания GPT).
- Llama Guard (для контроля ответов).
8. Заключение
Локальное развертывание DeepSeek или других LLM дает бизнесу полный контроль над ИИ, защищает данные и позволяет кастомизировать модель под свои нужды.
Если вы хотите узнать больше о внедрении ИИ в свою инфраструктуру, читайте наш блог – мы регулярно публикуем гайды и кейсы.
🚀 Готовы внедрить ИИ? Обращайтесь за консультацией!